去年在公司推广了robotframework自动化框架,基于此框架我们设计开发了HTTPTestLibrary关键字库开展接口测试,效果挺好。我们部门测试开发的统一Python版本为python2.7,因为在我来公司前就在用这个版本,虽然2020年社区不再提供支持,但我们目前还没有迁移Python3的计划,这是前提。
有点别致的JSON
说到接口测试,必然要支持解析处理各种请求体,其中,我们的研发在某些项目的接口中使用了这样的请求体,我举个例子:
1 | {"key1": 123, "trouble": "{\"inner\": \"hehe\"}"} |
JSON里嵌套一个JSON对象,还是个字符串型的,这是个标准的JSON类型嘛???google得知如下知识
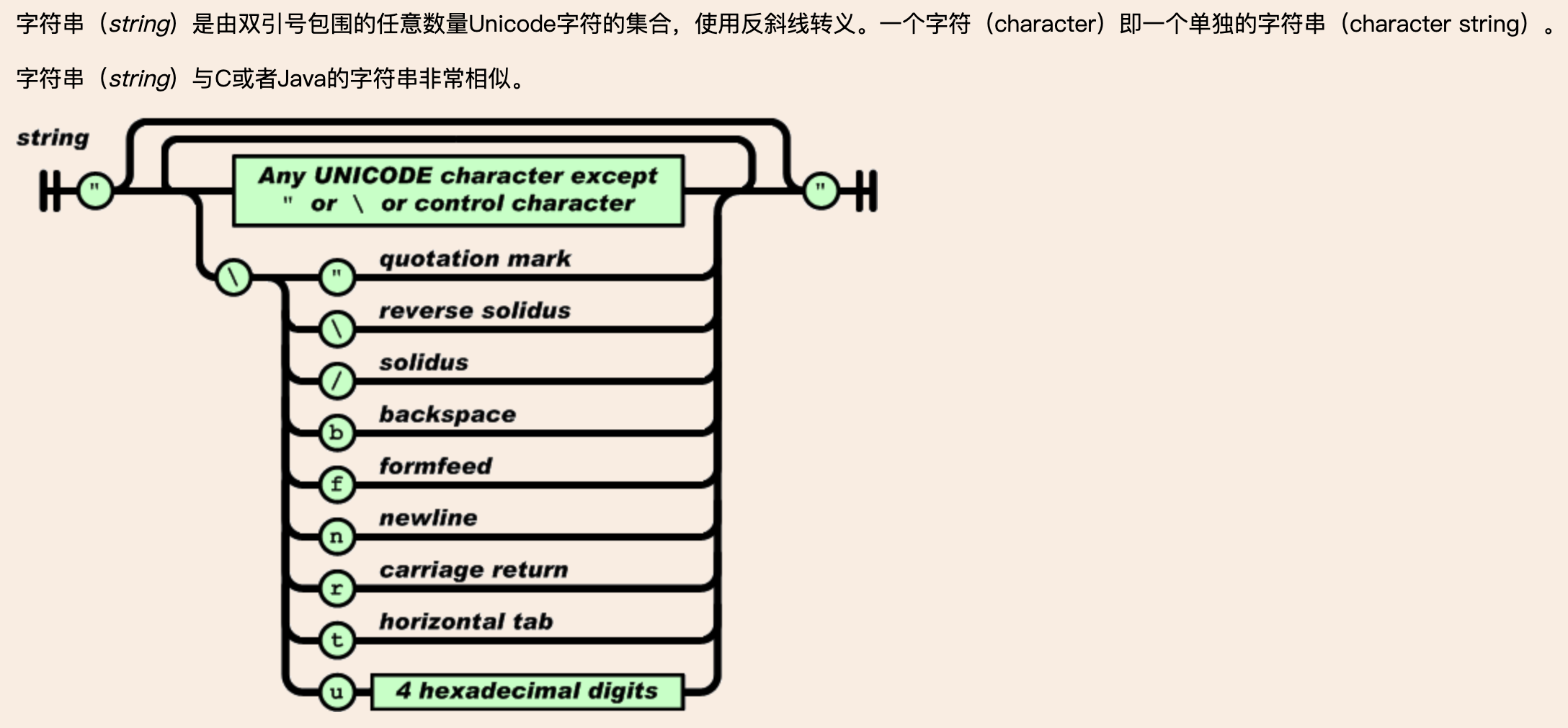
我们用Python测试下:
1 | In [8]: json_str = r'''{"key1": 123, "trouble": "{\"inner\": \"hehe\"}"}''' |
2 | |
3 | In [9]: json_str |
4 | Out[9]: '{"key1": 123, "trouble": "{\\"inner\\": \\"hehe\\"}"}' |
5 | |
6 | In [10]: print(json_str) |
7 | {"key1": 123, "trouble": "{\"inner\": \"hehe\"}"} |
8 | |
9 | In [11]: import json |
10 | |
11 | In [12]: json.loads(json_str) |
12 | Out[12]: {'key1': 123, 'trouble': '{"inner": "hehe"}'} |
13 | |
14 | In [13]: type(json.loads(json_str)) |
15 | Out[13]: dict |
研发定义的请求体没毛病,接下来看看我们的Python2的robotframework遇到什么问题了。
robotframework测试用例
我们的robotframework测试用例如下:
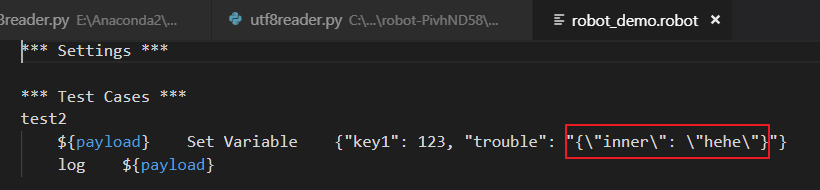
基于我们对robotframework的了解,robotframework会读取文本格式的robot测试用例,经过解析加载为内存对象,构建测试用例,我们先分别使用Python2和Python3读取测试用例,看看效果是什么样子:
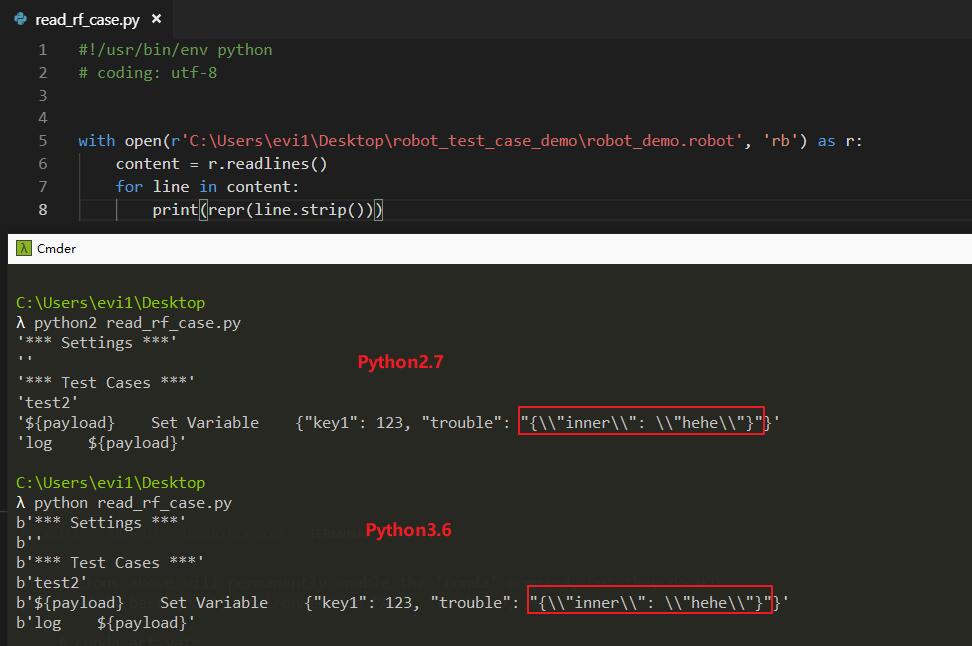
可以看到,虽然python2和python3对字符串的类型处理方式不同,但是对于我们的测试用例文本,都只进行了转译加上了一个\。
为了方便定位问题,便于观察,我们统一修改了robotframework的源码,增加了文本用例解析的输出
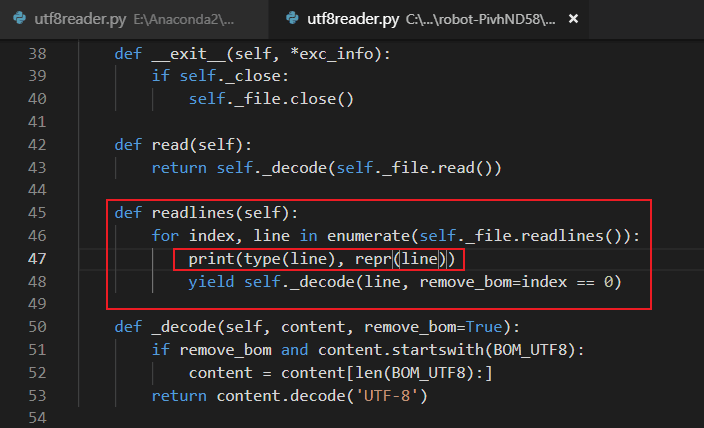
Python2版本的robotframework同学登场
先看下robotframework的测试执行结果,看起来没毛病。
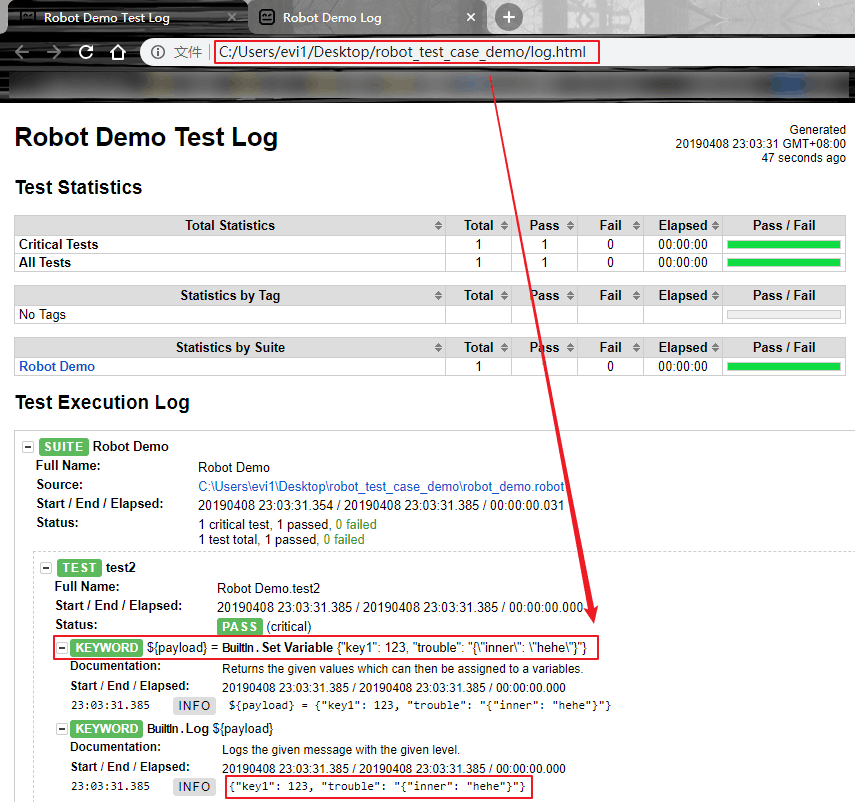
再看看测试用例的debug输出:
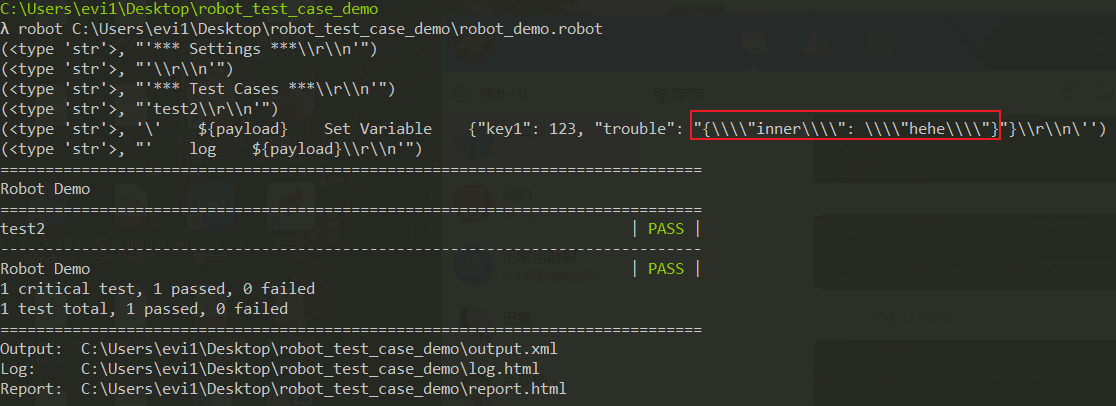
WTF!为神马变成了四个\???,这就是导致我们的请求体异常,接口响应错误的根本原因啊!
可是在上面的的Python2直接读取测试用例表现的不是这样啊!
稳住,我们不能冤枉Python2同学,我们看看Python3的表现。
Python3版本的robot framework同学低调入场
Python3版本我们使用pipenv创建了一个虚拟环境,同样也修改了robotframework的源码,输出repr
按惯例先看看Python3版本的robotframework的测试执行结果:
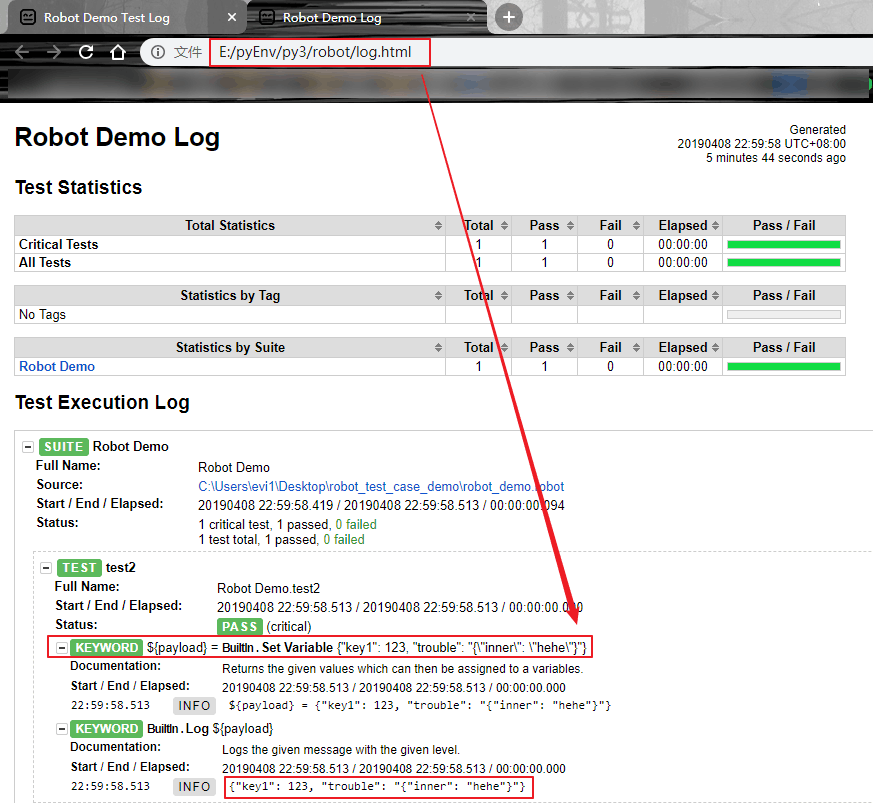
看起来和python2版本的一模一样,再看看测试用例的debug输出:
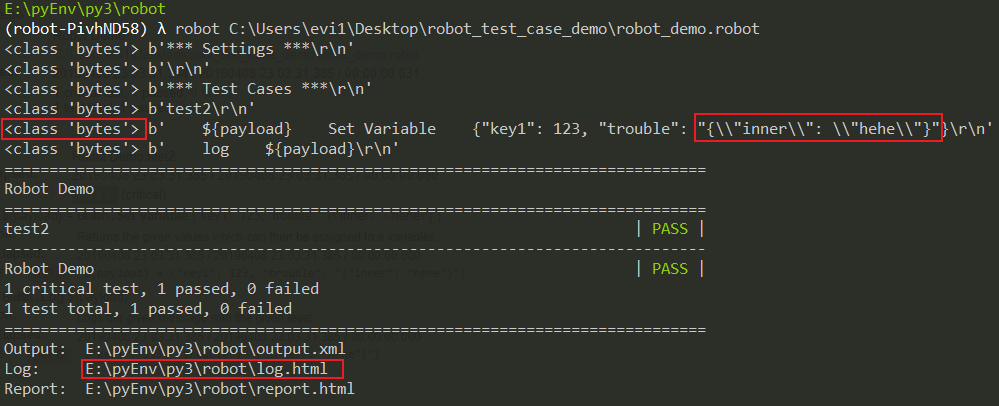
一切正常,完美!这样的结果才是我们想要的,这样的结果才能保证我们的接口响应正常。
蛛丝马迹
我们再仔细阅读下源码,robotframework到底是怎么读取的文本用例:
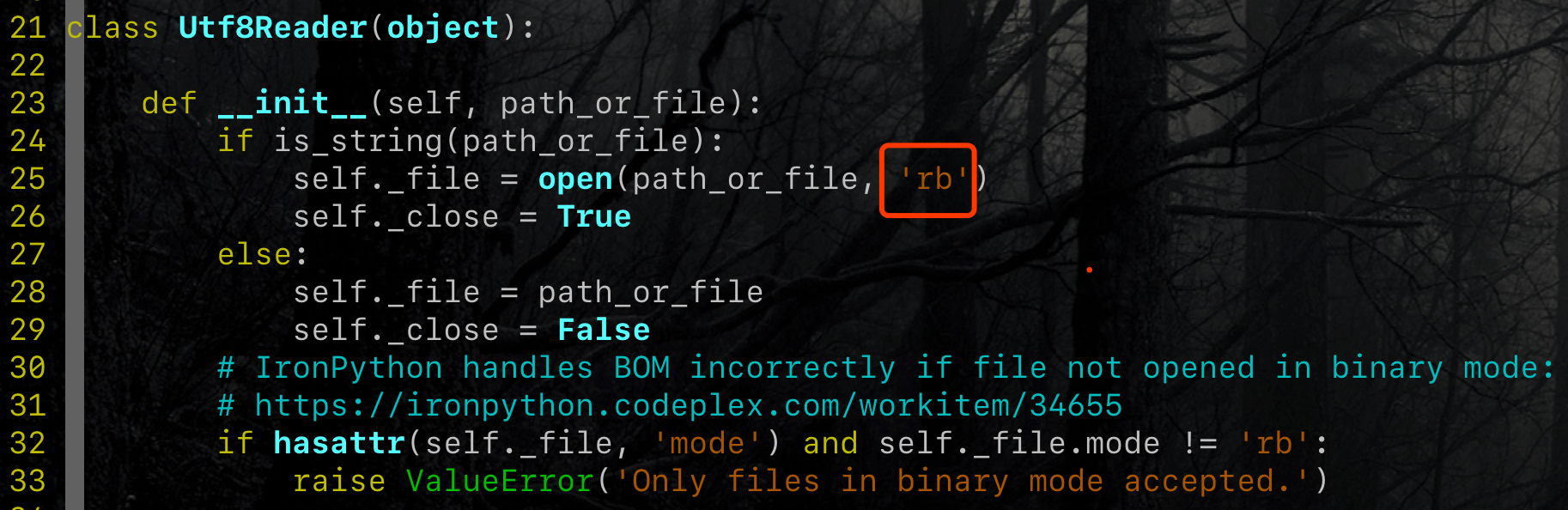
robotframework是以rb模式打开文件进行读取的。
Python官方文档是这么说的:
通常文件是以 text mode 打开的,这意味着从文件中读取或写入字符串时,都会以指定的编码方式进行编码。如果未指定编码格式,默认值与平台相关 (参见
open())。在mode 中追加的'b'则以 binary mode 打开文件:现在数据是以字节对象的形式进行读写的。这个模式应该用于所有不包含文本的文件。
但是我们进行debug输出时,python2版本却输出的是<type 'str'>类型,python3版本输出的是<class bytes>类型,显然Python2版本的robotframework在搞事情!
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。
至此,真相逐渐浮出水面了,不过我们还是不知道为什么Python2版本的robotframework会出现这种情况,但我们可以肯定的是,尽早的迁移到Python3,一定是一件正确的事情!
Reference
http://www.json.org/json-zh.html
https://blog.csdn.net/lgysjfs/article/details/86678559
http://www.ituring.com.cn/article/1116
https://stackoverflow.com/questions/9644110/difference-between-parsing-a-text-file-in-r-and-rb-mode/9644141#9644141
https://docs.python.org/zh-cn/3/tutorial/inputoutput.html#reading-and-writing-files
https://docs.python.org/zh-cn/2.7/tutorial/inputoutput.html#reading-and-writing-files