今天我们继续来搞Coding数据~
从官方给出的数据我们知道目前Coding大概有50万注册用户
然后我们还能看到冒泡广场有很多热门用户
那么这些用户之间的关系是什么样子滴?
哪些用户是高冷吸粉狂人?
哪些用户是社交达人?
哪些用户是万年潜水独行侠?
50万Coding小伙伴的社交网络核心是哪位?
是否真的有50万用户?
带着这些疑问,我们开始撸代码!
先把项目地址贴下:https://github.com/toddlerya/AnalyzeCoding
爬虫算法分析设计:
如何获取全部用户信息
通过分析Coding网站, 我们发现有3个地方可以获取到用户数据信息:
冒泡广场: 每一条冒泡都有
发布人,有些还有点赞人、打赏人、评论人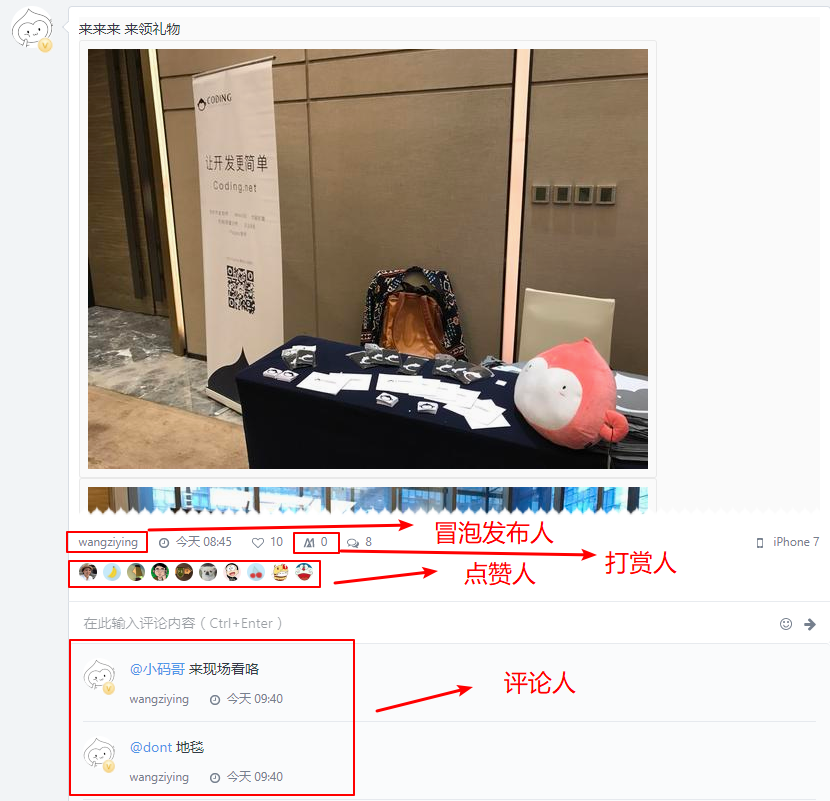
热门用户:冒泡广场首页右侧有20个热门用户,这些用户是当前最活跃的用户,这些用户拥有比较多的粉丝和朋友。
个人主页:用户的个人主页有一个标签页:
关注,这里可以看到此用户关注了哪些人,被哪些人关注。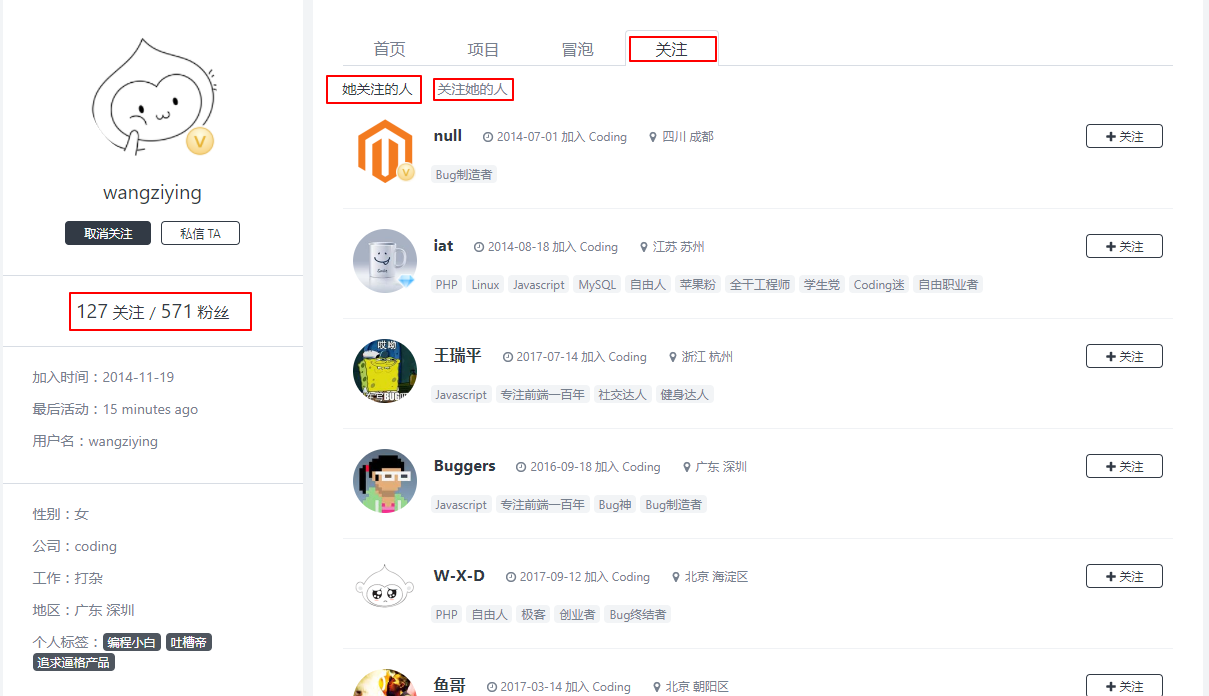
现在就是开脑洞的时候啦!
用户之间的关系分为三种:
1 | A关注B: A-->B |
2 | A被B关注:A<--B |
3 | A与B互相关注:A<-->B |
这就是个有向图嘛!
六度分隔理论:
1967年,哈佛大学的心理学教授Stanley Milgram(1933-1984)想要描绘一个连结人与社区的人际连系网。做过一次连锁信实验,结果发现了“六度分隔”现象。简单地说:“你和任何一个陌生人之间所间隔的人不会超过六个,也就是说,最多通过六个人你就能够认识任何一个陌生人。”
思路渐渐清晰了,我们可以采用深度优先算法(Depth-First Search,简称DFS)
从A出发,找到A所有的好友(A1,A2,A3)记录为{A: [A1, A2, A3]}
从A1出发,找到A1所有的好友(A,A2-1,A3-1)记录为{A1: [A, A2-1, A3-1]}
从A2-1出发,找到A2-1所有的好友(A2-1-1)记录为{A2-1: [A2-1-1]}
从A3-1出发,找到A3-1所有的好友(A3-1-1)记录为{A3-1: [A3-1-1]}
从A2出发,找到A2所有的好友(A2-1)记录为{A2: [A2-1]}
……循环递归……
直到Z,Z同学没有任何好友,结束本次遍历爬取。
爬取过程中要注意,已经爬取过的人要跳过,否则会陷入无限循环中。
相关API
- 当前热门用户:
https://coding.net/api/tweet/best_user - 用户的朋友们:
https://coding.net/api/user/friends/{用户全局唯一代号}?page=1&pageSize=20 - 用户的粉丝们:
https://coding.net/api/user/followers/{用户全局唯一代号}?page=1&pageSize=20 - 用户个人信息详情:
https://coding.net/api/user/key/{用户全局唯一代号}
代码设计实现
数据库设计
为了程序轻便,数据便于分享,我们决定使用Sqlite数据库。
上述分析过程中发送,用户的登录帐号是全局唯一的,不会重复的,我们以此字段作为主键且不允许为空,
还可以通过上述API获取用户的朋友、朋友的个数、用户的粉丝、粉丝的个数、用户详细信息,因此用户社交关系表设计如下:
1 | CREATE TABLE IF NOT EXISTS coding_all_user ( |
2 | global_key VARCHAR PRIMARY KEY NOT NULL, |
3 | friends_count INTEGER, |
4 | friends VARCHAR, |
5 | followers_count INTEGER, |
6 | followers VARCHAR |
7 | ) |
用户个人信息详情表设计如下:
1 | CREATE TABLE IF NOT EXISTS coding_user_info ( |
2 | global_key VARCHAR PRIMARY KEY NOT NULL, |
3 | user_name VARCHAR, |
4 | name_pinyin VARCHAR, |
5 | sex VARCHAR, |
6 | slogan VARCHAR, |
7 | company VARCHAR, |
8 | job VARCHAR, |
9 | tags VARCHAR, |
10 | skills VARCHAR, |
11 | website VARCHAR, |
12 | introduction VARCHAR, |
13 | avatar VARCHAR, |
14 | school VARCHAR, |
15 | follows_count VARCHAR, |
16 | fans_count INTEGER, |
17 | tweets_count INTEGER, |
18 | vip VARCHAR, |
19 | created_at VARCHAR, |
20 | last_logined_at VARCHAR, |
21 | last_activity_at VARCHAR |
22 | ) |
爬虫设计
这里要注意有一个特殊的用户coding,此用户为官方帐号,此用户的friends和followers两个API数据为空,遇到此用户要进行跳过。
根节点设置
第一次爬取,将当前热门用户作为起始根节点,后续取数据库中已经存储的用户与当前热门用户比较,若当前热门用户有未录入数据库的,则以当前热门用户作为根节点,否则以数据库中的用户作为根节点启动爬虫。
遍历用户爬虫(crawl_all_user.py)执行逻辑
爬取每一个节点的好友、粉丝,入库(coding_all_user)更新(因为用户的好友和粉丝会变化)、若其好友未录入数据库,则加入下一轮递归抓取的任务列表,否则结束此轮任务。
用户详细信息爬虫(crawl_user_info.py)逻辑
以遍历用户爬虫录入的coding_all_user表作为输入数据,遍历库中的每一个用户,通过用户个人信息详情API来获取用户信息录入coding_user_info表
遇到的问题:
1. python递归深度报错
- 报错详情:
1--RuntimeError: maximum recursion depth exceeded - 问题原因:
python默认的递归深度是1000,因此当递归深度超过999的时,就会引发这样的一个异常。
从Coding的官方公布数据了解到,Coding目前有50万用户,所以当程序爬取到第1000个人以后肯定就报错崩溃啦! - 解决方案:
粗暴的将默认递归深度调大点经过尝试我们发现Python可以递归的最大深度为21474836471import sys2sys.setrecursionlimit(1000000) #例如这里设置为一百万
大于此深度,设置时会报错:但是!但是!这不是正确的解决方案,正确的解决方案应该是优化代码,使用生成器+循环来解决问题!1OverflowError: signed integer is greater than maximum # Linux2OverflowError: Python int too large to convert to C long # Windows
部分代码
crawl_all_user.py
crawl_user_info.py