项目地址: https://github.com/toddlerya/learn_scrapy
I. Coding的冒泡广场
CODING 是国内专业的一站式云端软件服务平台,Coding.net 为开发者提供了免费的基础服务,包括但不限于 Git 代码托管,项目管理,Pages 服务,代码质量管理。您可以在 Coding.net 一站完成代码及代码质量,项目及项目人员的管理,Coding.net 让开发变得前所未有的敏捷和简单。
其中Coding有一个冒泡的社交功能– 冒泡广场,比较像微博,会有很多程序员的日常吐槽,分享等,比如这样:
这里面的数据属性非常丰富,每一条冒泡都具有如下属性: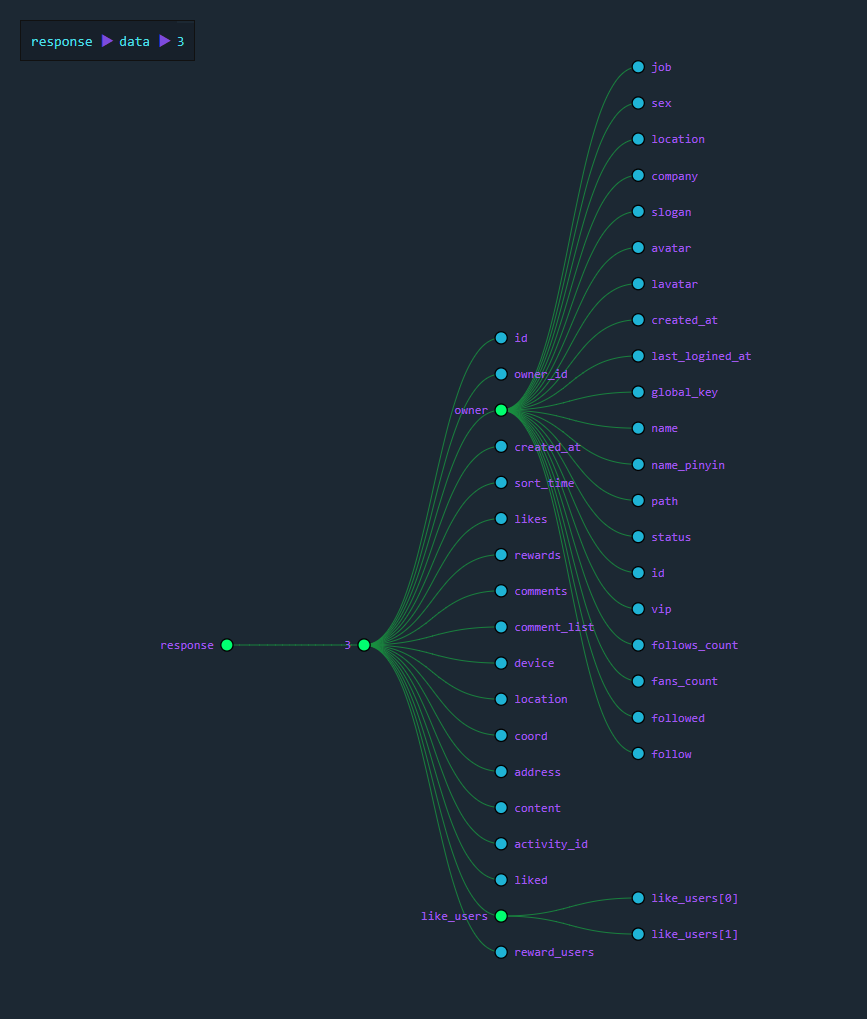
1. 爬虫分析
爬虫的基本原则是能使用API接口,绝不解析html页面,恰巧这个网站的API很好用。
对这个网站的API进行了基本的分析:
html https://coding.net/api/tweet/public_tweets?size=20&sort=time&filter=true&last_time=1504876265000分析发现只需提交size和filter参数即可:
- filter=true为只获取精华冒泡,false为获取全量,当然是全量啦!
- size为最近发表的多少条冒泡信息
因此最终的get 请求为:
https://coding.net/api/tweet/public_tweets?size=20&filter=false
2. 这里有两个注意事项
- 网站的rebots.txt设置了规则,禁止爬取
Disallow: /api/*,我们只是做个小实验,不进行大规模的爬取,因此需要修改下Scrapy项目的settings.py配置(不守规矩~):1# Obey robots.txt rules2ROBOTSTXT_OBEY = False - size参数如果太大会导致HTTP访问超时,Scrapy报错中止,需要在请求发起时修改Request.meta的参数,见官方文档:DOWNLOAD_TIMEOUT
1[scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://coding.net/api/tweet/public_tweets?size=100000&filter=false> (failed 1 times): 504 Gateway Time-out